



Manim Inheritance Graph
NumVue #2 - Interaction Loop

In the last post we made the following conclusions:
Specifying animation content is hard: For programmatic animation renders, it is difficult to use ad hoc data structures to consistently relate program instructions to animation forms.
Modifying animation content at a granular level for code sequences is hard: For existing animation configurations, this includes inserting complex elements in the right sequence at the right level of abstraction. An example may include adding the rotational element to a cube rendered in a previous interaction loop while leaving the angle of the camera and the dimensions of space unchanged.
NumVue’s Experimental Interaction Loop:
User expresses animation specifications using natural language.
NumVue translates specifications into Python code.
Generated code is interpreted as a concurrent subprocess within the ChatGPT API thread’s environment.
Rendered video is presented to user (or stored elsewhere in case of programmatic use.)
At the present moment, our intermediate representation is the code itself. While it is a fine approach for general-purpose scripts, we need to ensure that the generated instructions are sequentially consistent and also contain rendering instructions for the substance of animations.
In other words, we are reasoning about the linguistic characteristics of programs using large language models, both the syntax and the semantics.
For syntactic consistency, we consider the instructions and their order. For example, if the user were to prompt NumVue to generate a sine wave followed by a circle, the resulting code variations over time can change the order. We need a reliable means to assess these variations over time.
In terms of semantics, we consider the arguments passed to active elements, which are the basic elements from Manim (such as MObject, Shape, Axes, Polygon, Graph, Camera, Scene/ThreeDScene … to denote positively defined elements — elemental forms — upon which operations are applied.)
Why Not Fine-Tune LLMs?
Although ChatGPT-4 has Bing Search capabilities, primary observations over several trials showed a resolution limit for the model’s search space in terms of scraping API docs through the chat interface. It is possible, in principle, to ask ChatGPT (or any other LLM such as Bard, Llama, …) to scrape specific webpages for specific elements after parsing the webpage’s text content using more traditional statistical natural language processing techniques. Such structured data could be used as a fine-tuning corpus for domain-specific applicability.
Nonetheless, the problems of intermediate representation and ad hoc code modifications while preserving sequential semantics and syntax remain.
We seek to establish a baseline system that remains modular enough for fine-tuned models in the future. For now, we discuss the theoretical elements and preconditions for a potential system that satisfies said design constraints.
Manim Inheritance Graph
We generate a foundational abstract syntax tree for the nested structure of a Manim Scene’s elements.
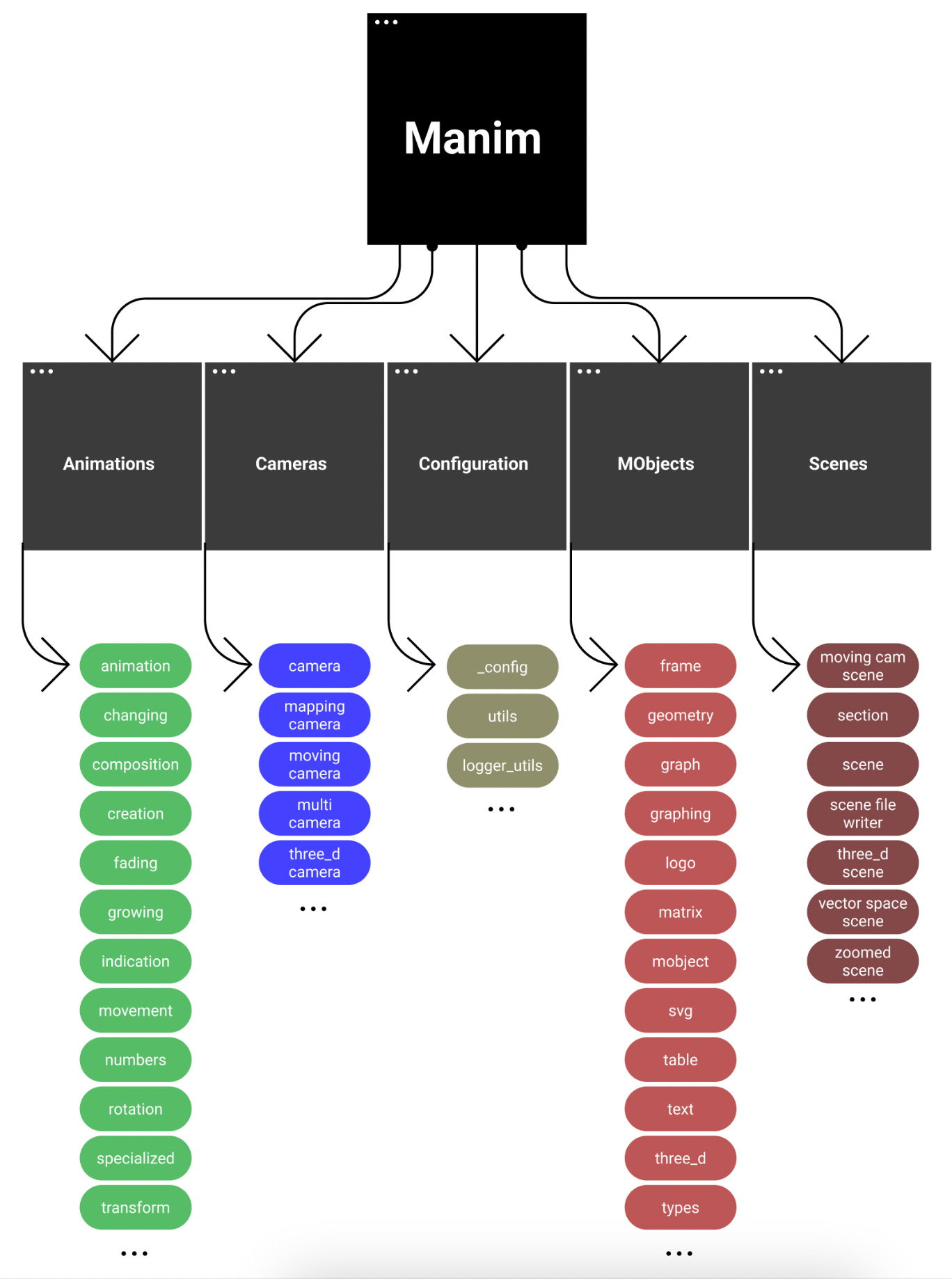
Source: Manim CE Docs
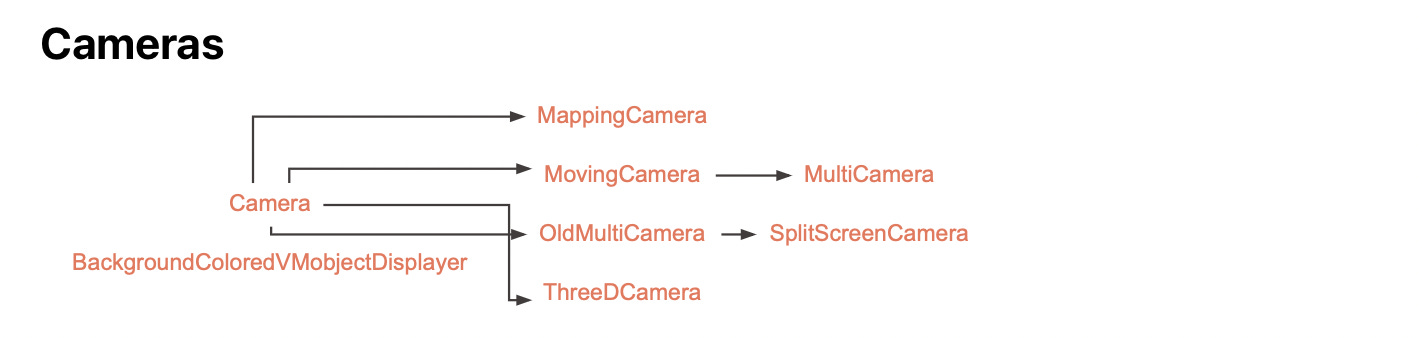

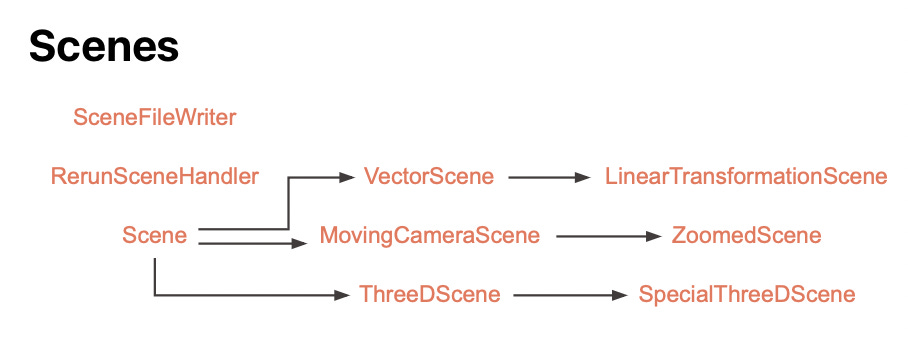
Source: Manim CE DocsThe graphs above demonstrate the complexities involved in dependency management during CRUD operations within code regeneration interaction loops. For example, if the first version of an animation script is set inside 2D space, then subsequent edits to transition into 3D space will require a change in the script’s inherited class from Scene to ThreeDScene.
Intra-Domain Dependencies
Similarly, the user’s original specification may contain ambiguities that stochastically triangulate different elements with varying parent nodes. Thus, edits are not simply limited to modifying one line of code with another. Rather, they require a real-time representation of the dependencies within code such that any logic for the code’s procedural and functional semantics is represented and transformed outside the code’s linguistic context.
This might imply introducing an intermediate layer that stores and processes the inheritance patterns to bridge the user prompt and code generation layers. This is how the existing interaction loop would change if we were to incorporate these findings:
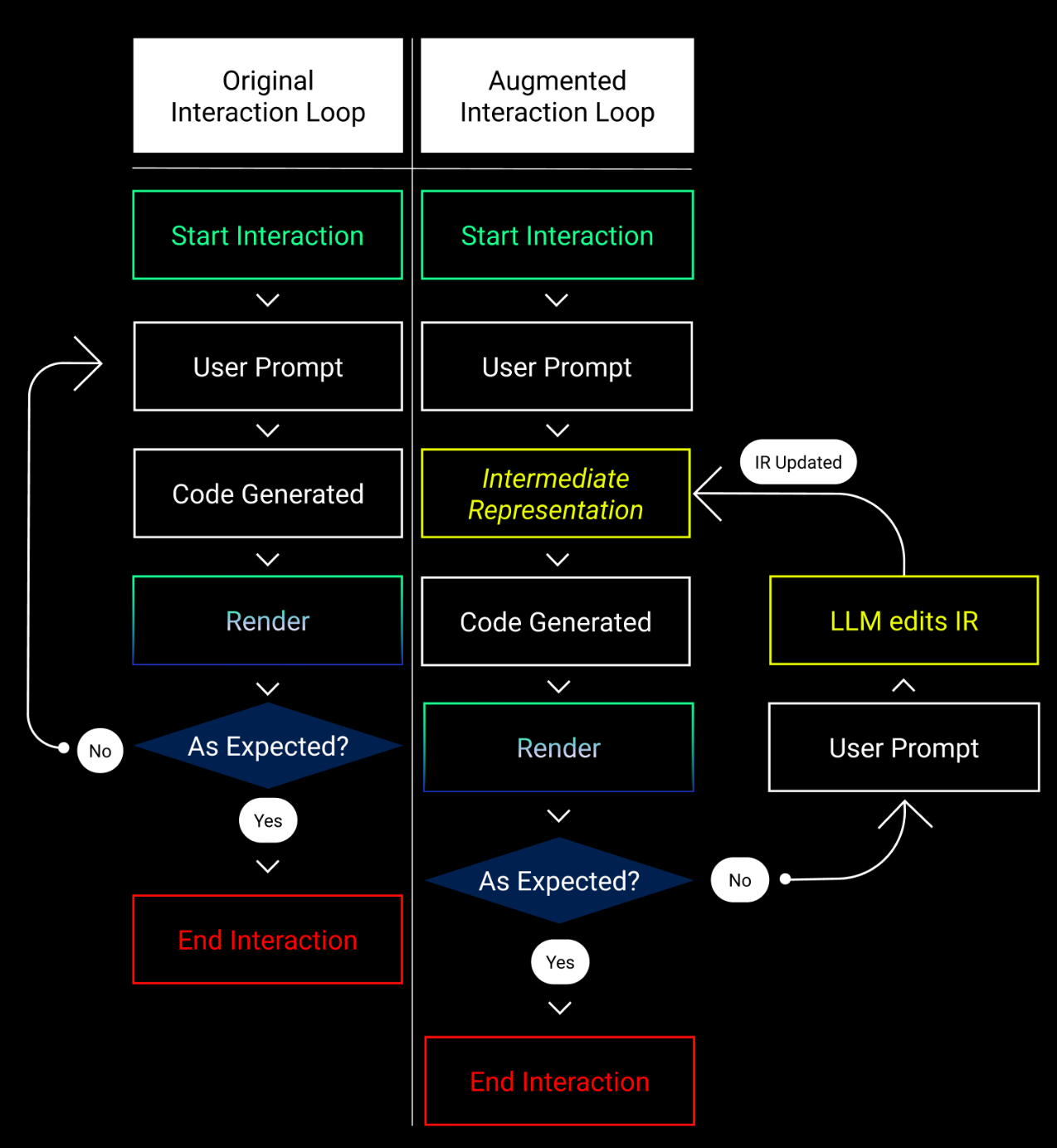
In the initial interaction loop, the user has to restart their journey by refining the animation prompt. This also results in procedural semantic inconsistencies.
The augmented interaction loop incorporates an LLM-IR interface, such that the model generates elements designed for the Manim syntax tree while preserving fundamental elements that work well, such as the camera, scene, axes, text, and so forth.
Therefore, we need a modular interface between the Manim syntax tree and ChatGPT to translate ad hoc user prompted modifications to existing code without referencing the code directly. We do so to comply with the design requirements outlined earlier.
Up Next
Embeddings for Syntax Trees
Quantitatively assessing embeddings
Translating IR updates into interspersed code
Procedural semantic consistency
[Everything written here is a personal reflection on a personal publishing channel. Do not reproduce without written permission from the author.]
Cover photo by Jeremy Bishop on Unsplash.